
How to scrape a website that requires login with Python
I’ve recently had to perform some web scraping from a site that required login. It wasn’t very straight forward as I expected so I’ve decided to write a tutorial for it.
For this tutorial we will scrape a list of projects from our bitbucket account.
The code from this tutorial can be found on my Github.
We will perform the following steps:
- Extract the details that we need for the login
- Perform login to the site
- Scrape the required data
For this tutorial, I’ve used the following packages (can be found in the requirements.txt):
requests
lxmlStep 1: Study the website
Open the login page
Go to the following page “bitbucket.org/account/signin” .
You will see the following page (perform logout in case you’re already logged in)
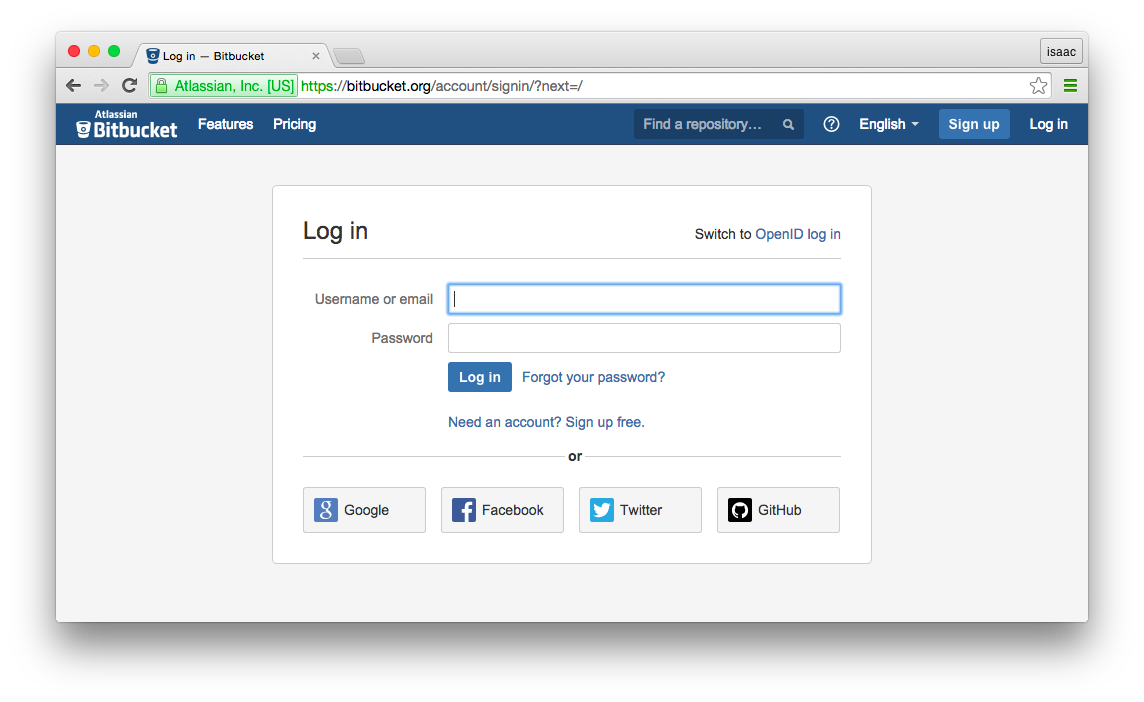
Check the details that we need to extract in order to login
In this section we will build a dictionary that will hold our details for performing login:
- Right click on the “Username or email” field and select “inspect element”. We will use the value of the “name” attribue for this input which is “username”. “username” will be the key and our user name / email will be the value (on other sites this might be “email”, “user_name”, “login”, etc.).
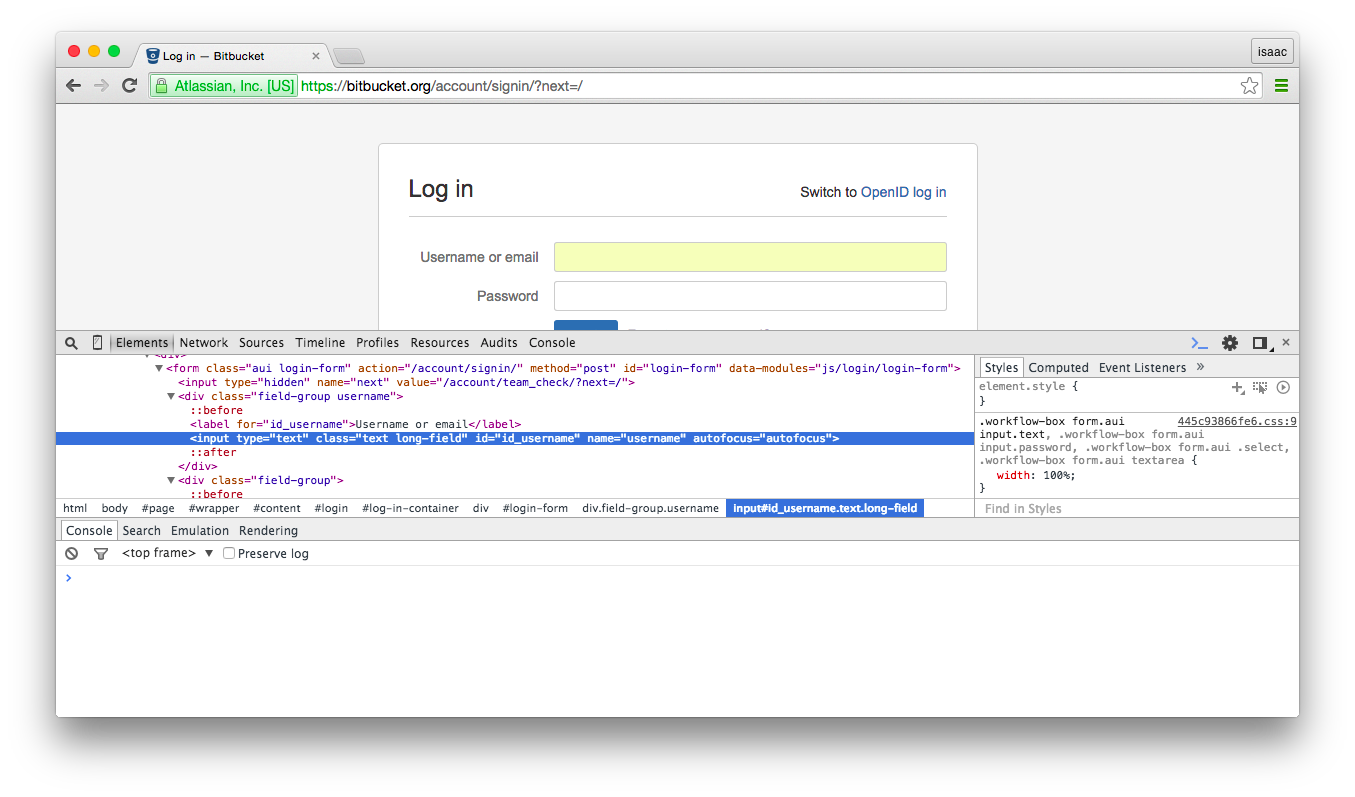

- Right click on the “Password” field and select “inspect element”. In the script we will need to use the value of the “name” attribue for this input which is “password”. “password” will be the key in the dictionary and our password will be the value (on other sites this might be “user_password”, “login_password”, “pwd”, etc.).
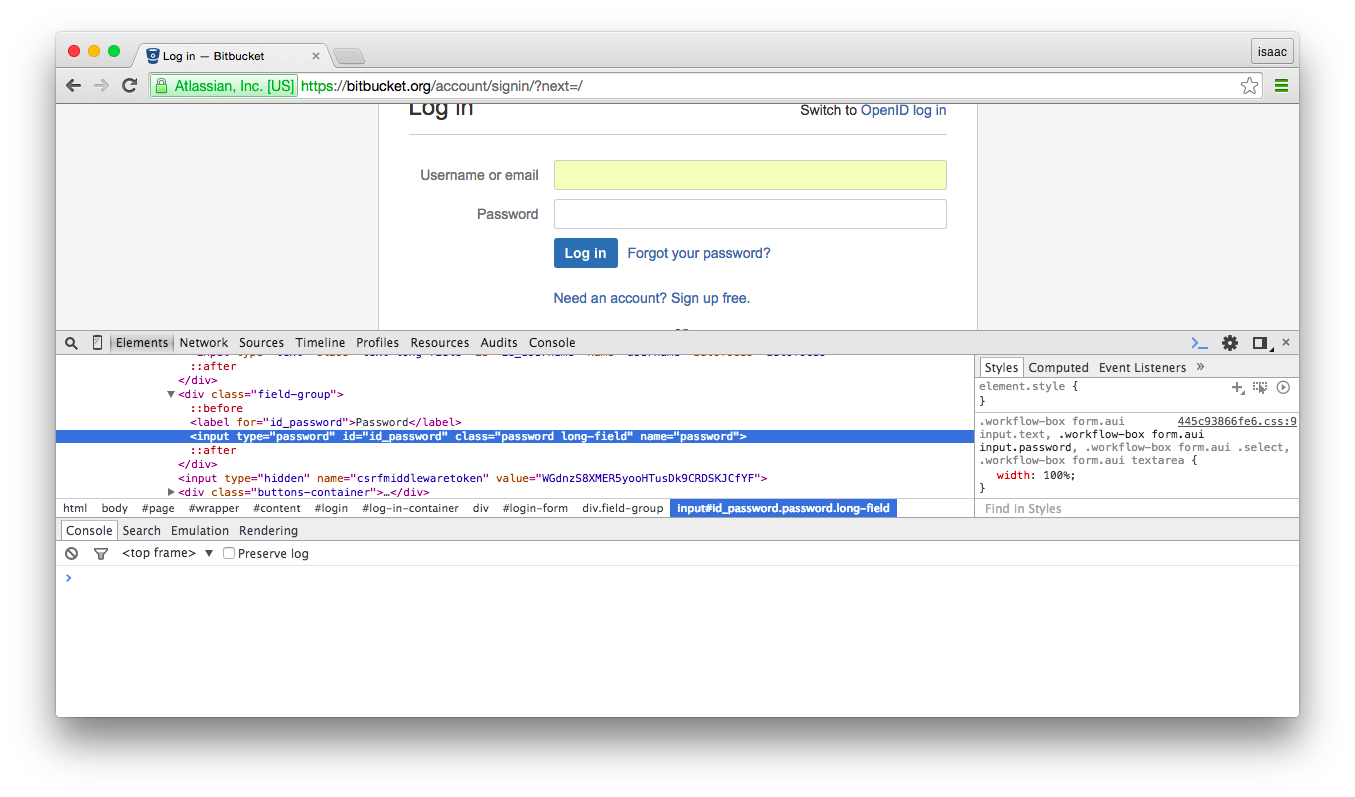

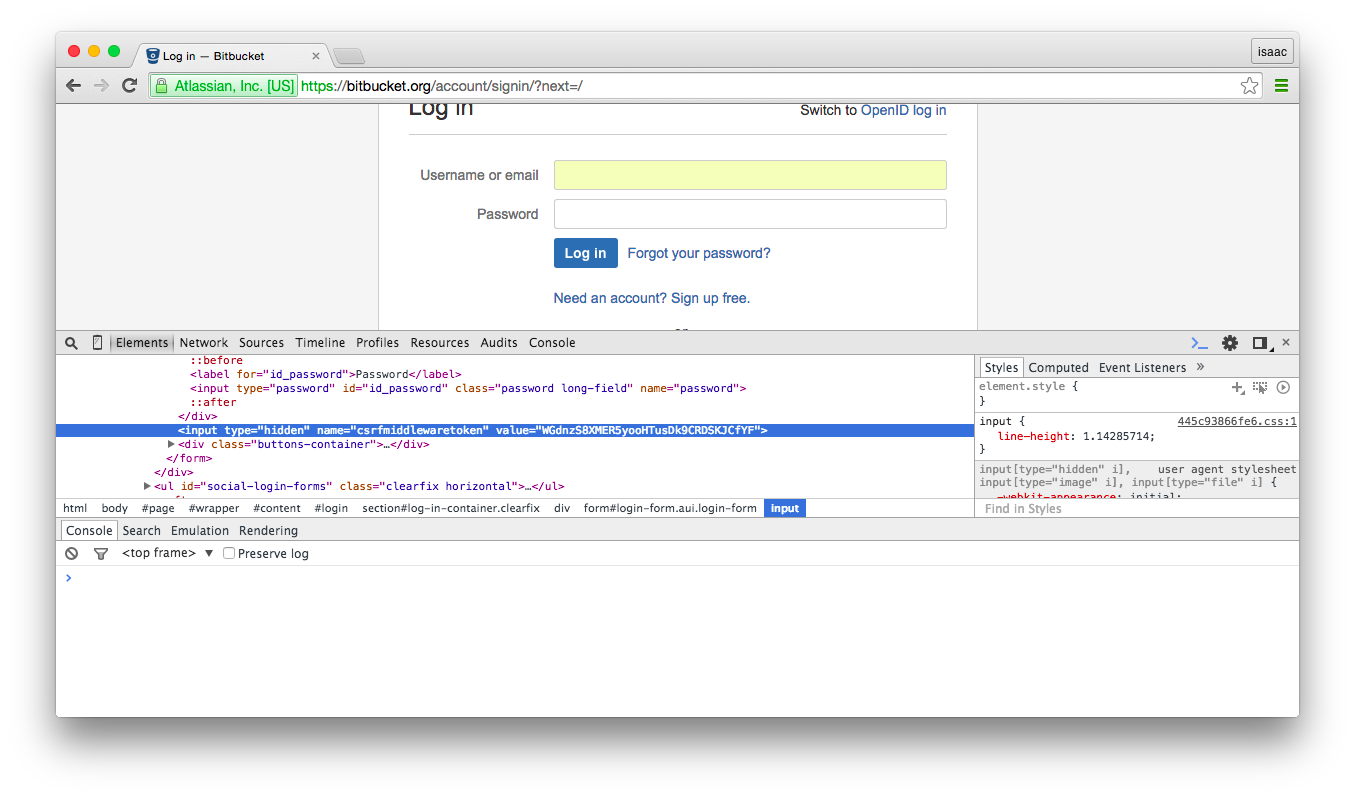
- In the page source, search for a hidden input tag called “csrfmiddlewaretoken”. “csrfmiddlewaretoken” will be the key and value will be the hidden input value (on other sites this might be a hidden input with the name “csrf_token”, “authentication_token”, etc.). For example “Vy00PE3Ra6aISwKBrPn72SFml00IcUV8”.

We will end up with a dict that will look like this:
payload = {
"username": "<USER NAME>",
"password": "<PASSWORD>",
"csrfmiddlewaretoken": "<CSRF_TOKEN>"
}Keep in mind that this is the specific case for this site. While this login form is simple, other sites might require us to check the request log of the browser and find the relevant keys and values that we should use for the login step.
Step 2: Perform login to the site
For this script we will only need to import the following:
import requests
from lxml import htmlFirst, we would like to create our session object. This object will allow us to persist the login session across all our requests.
session_requests = requests.session()Second, we would like to extract the csrf token from the web page, this token is used during login. For this example we are using lxml and xpath, we could have used regular expression or any other method that will extract this data.
login_url = "https://bitbucket.org/account/signin/?next=/"
result = session_requests.get(login_url)
tree = html.fromstring(result.text)
authenticity_token = list(set(tree.xpath("//input[@name='csrfmiddlewaretoken']/@value")))[0]** More about xpath and lxml can be found here.
Next, we would like to perform the login phase. In this phase, we send a POST request to the login url. We use the payload that we created in the previous step as the data. We also use a header for the request and add a referer key to it for the same url.
result = session_requests.post(
login_url,
data = payload,
headers = dict(referer=login_url)
)Step 3: Scrape content
Now, that we were able to successfully login, we will perform the actual scraping from bitbucket dashboard page
url = 'https://bitbucket.org/dashboard/overview'
result = session_requests.get(
url,
headers = dict(referer = url)
)In order to test this, let’s scrape the list of projects from the bitbucket dashboard page. Again, we will use xpath to find the target elements and print out the results. If everything went OK, the output should be the list of buckets / project that are in your bitbucket account.
tree = html.fromstring(result.content)
bucket_names = tree.xpath("//div[@class='repo-list--repo']/a/text()")
print(bucket_names)You can also validate the requests results by checking the returned status code from each request. It won’t always let you know that the login phase was successful but it can be used as an indicator.
for example:
result.ok # Will tell us if the last request was ok
result.status_code # Will give us the status from the last requestThat’s it.
Full code sample can be found on Github.