
Scrape country data from Wikipedia
Someone recently asked me if there’s a way to translate a 2 letter country code (i.e. US) to a country name (i.e. United States), and similarly, if there’s a way to translate a 3 letter country code (i.e. CAN) to a country name (i.e. Canada).
Wikipedia has a page that lists different data properties for each country. This data include country codes, mobile country code, country top level domain, etc.
In this tutorial we will scrape Wikipedia for the information about each country, and then translate between the different possible country names. We will perform the following steps:
- The countries are listed in different pages on Wikipedia, so we will first get the urls for all these pages automatically
- We will iterate over all of these urls and extract the listed details for each country
- Save the results in a file
- Load the data from the file and create an object that translates a country code to a full country name
The code for this tutorial can be found on Github.
Requirements
The code uses the following packages (can be found in the requirements.txt):
bs4
json
requests
argparseStep 1: Get urls for all countries
First, we will extract all the urls for the countries’ data.
In order to do that we will fetch the Wikipedia page using the requests module. After that we will use BeautifulSoup to create a soup object from the content of the page. The soup object will help us to easily retrieve the data that we want from the HTML.
url = "https://en.wikipedia.org/wiki/Country_code"
response = requests.get(url)
soup = bs4.BeautifulSoup(response.text, "html.parser")Next, we will want to extract the country pages urls from the “Lists of country codes by country” section of the page.
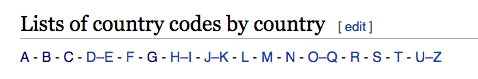
In the page source, the data that we want to extract looks like this:
<a href="/wiki/Country_codes:_A" title="Country codes: A">A</a> -
<a href="/wiki/Country_codes:_B" title="Country codes: B">B</a> -
<a href="/wiki/Country_codes:_C" title="Country codes: C">C</a> -
<a href="/wiki/Country_codes:_D%E2%80%93E" title="Country codes: D–E">D–E</a> -
<a href="/wiki/Country_codes:_F" title="Country codes: F">F</a> -
<a href="/wiki/Country_codes:_G" title="Country codes: G">G</a> -
<a href="/wiki/Country_codes:_H%E2%80%93I" title="Country codes: H–I">H–I</a> -
<a href="/wiki/Country_codes:_J%E2%80%93K" title="Country codes: J–K">J–K</a> -
<a href="/wiki/Country_codes:_L" title="Country codes: L">L</a> -
<a href="/wiki/Country_codes:_M" title="Country codes: M">M</a> -
<a href="/wiki/Country_codes:_N" title="Country codes: N">N</a> -
<a href="/wiki/Country_codes:_O%E2%80%93Q" title="Country codes: O–Q">O–Q</a> -
<a href="/wiki/Country_codes:_R" title="Country codes: R">R</a> -
<a href="/wiki/Country_codes:_S" title="Country codes: S">S</a> -
<a href="/wiki/Country_codes:_T" title="Country codes: T">T</a> -
<a href="/wiki/Country_codes:_U%E2%80%93Z" title="Country codes: U–Z">U–Z</a></p>We can see that for each letter we have an <a> tag with “href” that has the following template "/wiki/Country_codes:_<LETTER / LETTER RANGE>". We want the “href” values of these <a> tags, they will lead us to the country data.
In the next one liner we perform the following actions:
- soup.findAll(‘a’) - extracts all the
<a>tags from the page. a_elem.attrs.get(‘href’, ‘’).startswith('/wiki/Country_codes') - we check for eacha_elemthat the has a “href” attribute and starts with"/wiki/Country_codes".- Save the “href” of the
a_elemthat fulfills the required condition incountries_urls.
countries_urls = [a_elem['href'] for a_elem in soup.findAll('a') if a_elem.attrs.get('href', '').startswith('/wiki/Country_codes')]After running this line, "countries_urls" should have the following values:
countries_urls = [
"/wiki/Country_codes:_A",
"/wiki/Country_codes:_B",
"/wiki/Country_codes:_C",
"/wiki/Country_codes:_D%E2%80%93E",
"/wiki/Country_codes:_F",
"/wiki/Country_codes:_G",
"/wiki/Country_codes:_H%E2%80%93I",
"/wiki/Country_codes:_J%E2%80%93K",
"/wiki/Country_codes:_L",
"/wiki/Country_codes:_M",
"/wiki/Country_codes:_N",
"/wiki/Country_codes:_O%E2%80%93Q",
"/wiki/Country_codes:_R",
"/wiki/Country_codes:_S",
"/wiki/Country_codes:_T",
"/wiki/Country_codes:_U%E2%80%93Z"
]Step 2: Get the details for each country
Now that we have all the urls for the country data saved in “countries_urls“, we will extract the data that we actually want from these urls.
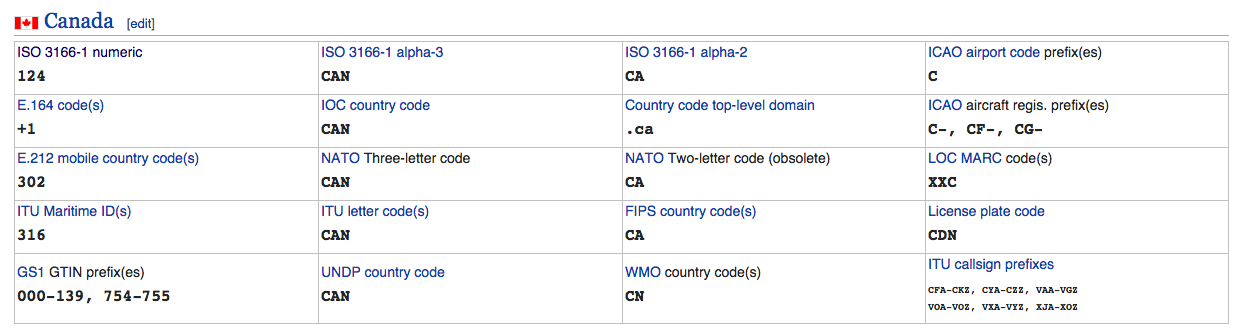
Each url holds a list of countries and information about them. You can see examples of how this data looks in the following page or in the following image:
In the code we’ll create a new function called “scrape_countries_details“.
This function will help us collect the data for all of the countries from each url.
We will use the function as we iterate on the urls that we fetched in step 1.
The “scrape_countries_details“ function will return a list of country data from the url.
We will save these results in the “all_countries_details“ list.
all_countries_details = []
for countries_url in countries_urls:
countries_data = scrape_countries_details(BASE_URL + countries_url)
all_countries_details.extend(countries_data)The "scrape_countries_details" function will work in the following way:
1) Get the url content and convert it to a soup object
# Get remote page
response = requests.get(url)
# Create soup object from page content
soup = bs4.BeautifulSoup(response.text, "html.parser")2) Fetch all elements that hold country names
# Fetch all elements that hold country names
country_names_elems = soup.findAll('span', 'mw-headline')3) Iterate over "country_names_elems" and for each "country_name_elem" retrieve the relevant table of contents
# Find the next table element after country name while holds
# the country's data
country_table = country_name_elem.parent.findNext("table")4) From the country’s data table, retrieve all the cells and create a dictionary, “country_data”, from the keys (cell names) and values (cell values) in the table
# Fetch all the cells in the table
tds = country_table.findAll("td")
# Each cell holds the cell name and the value
# so we can create a dict by reading each cell
# with the cell name as the key and the cell data as the value
country_data = {td.find("a").text: td.find("span").text for td in tds}5) Add the country name and Wikipedia page url for the country to "country_data" dictionary from the "country_name_elem" object
country_a_elem = country_name_elem.find('a')
country_data["country_name"] = country_a_elem.text.replace("\n", "").strip()
country_data["country_url"] = BASE_URL + country_a_elem['href']6) Add the "country_data" to the "countries_data" list that will contain all the countries and their data from the page. This list will be the output of the function.
countries_data.append(country_data)A full resolution of the function’s code:
def scrape_countries_details(url):
# Get remote page
response = requests.get(url)
# Create soup object from page content
soup = bs4.BeautifulSoup(response.text, "html.parser")
countries_data = []
# Fetch all elements that holds country name
country_names_elems = soup.findAll('span', 'mw-headline')
# For each country element retrieve all the relevant data
for country_name_elem in country_names_elems:
# Find the next table element after country name while holds
# the country's data
country_table = country_name_elem.parent.findNext("table")
if not country_table:
continue
# Fetch all the cells in the table
tds = country_table.findAll("td")
# Each cell holds the column name and the value
# so we can create a dict by reading each cell
# with the column name as the key and the cell data as the value
country_data = {td.find("a").text: td.find("span").text for td in tds}
# Add the country name and wikipedia page url for the country
country_a_elem = country_name_elem.find('a')
country_data["country_name"] = country_a_elem.text.replace("\n", "").strip()
country_data["country_url"] = BASE_URL + country_a_elem['href']
countries_data.append(country_data)
return countries_dataIn the end we will want to save our data in a file so we can use it later.
with open(output_file_path, "wb") as output_file:
json.dump(all_countries_details, output_file)Code for this part can be found here
Step 3: Create country code translator
Once we have a file with all the country data, we can create our country code translator. We want to create an object that will resolve every type of country code to the country name. For example, we want to be to do the following translations:
- “US” => “United States”
- “USA” = > “United States”
- “ca” => “Canada”
- “can” => “Canada”
In order to do that, we’ll create an object that gets a file path and loads the data from the file:
class CountryDataCodes(object):
def __init__(self, input_file_path):
with open(input_file_path, "rb") as input_file:
self._countries_data = json.load(input_file)The next code is for creating dictionaries that will allow us to do the following:
- Translate between 2 letter country code to country name (using the ‘ISO 3166-1 alpha-2’ values from each country)
- Translate between 3 letter country code to country name (using the ‘ISO 3166-1 alpha-3’ values from each country)
- Translate country name to country details.
self._countries_data = {country_data["country_name"].lower(): country_data for country_data in self._countries_data}
self._alpha_two_to_country_name = {}
self._alpha_three_to_country_name = {}
for country_name, country_data in self._countries_data.items():
alpha_two = country_data['ISO 3166-1 alpha-2']
alpha_three = country_data['ISO 3166-1 alpha-3']
self._alpha_two_to_country_name[alpha_two.lower()] = country_name
self._alpha_three_to_country_name[alpha_three.lower()] = country_nameWe will also create a function for retrieving country details no matter what type of country name we choose:
- 2 letter country code
- 3 letter country code
- country name
def get_country_details(self, value):
value = value.lower().strip()
if len(value) == 2:
country_name = self._alpha_two_to_country_name.get(value, None)
elif len(value) == 3:
country_name = self._alpha_three_to_country_name.get(value, None)
else:
country_name = value
country_data = self._countries_data.get(country_name)
return country_dataCode for this part can be found here
That’s it!
Full code sample can be found on Github.